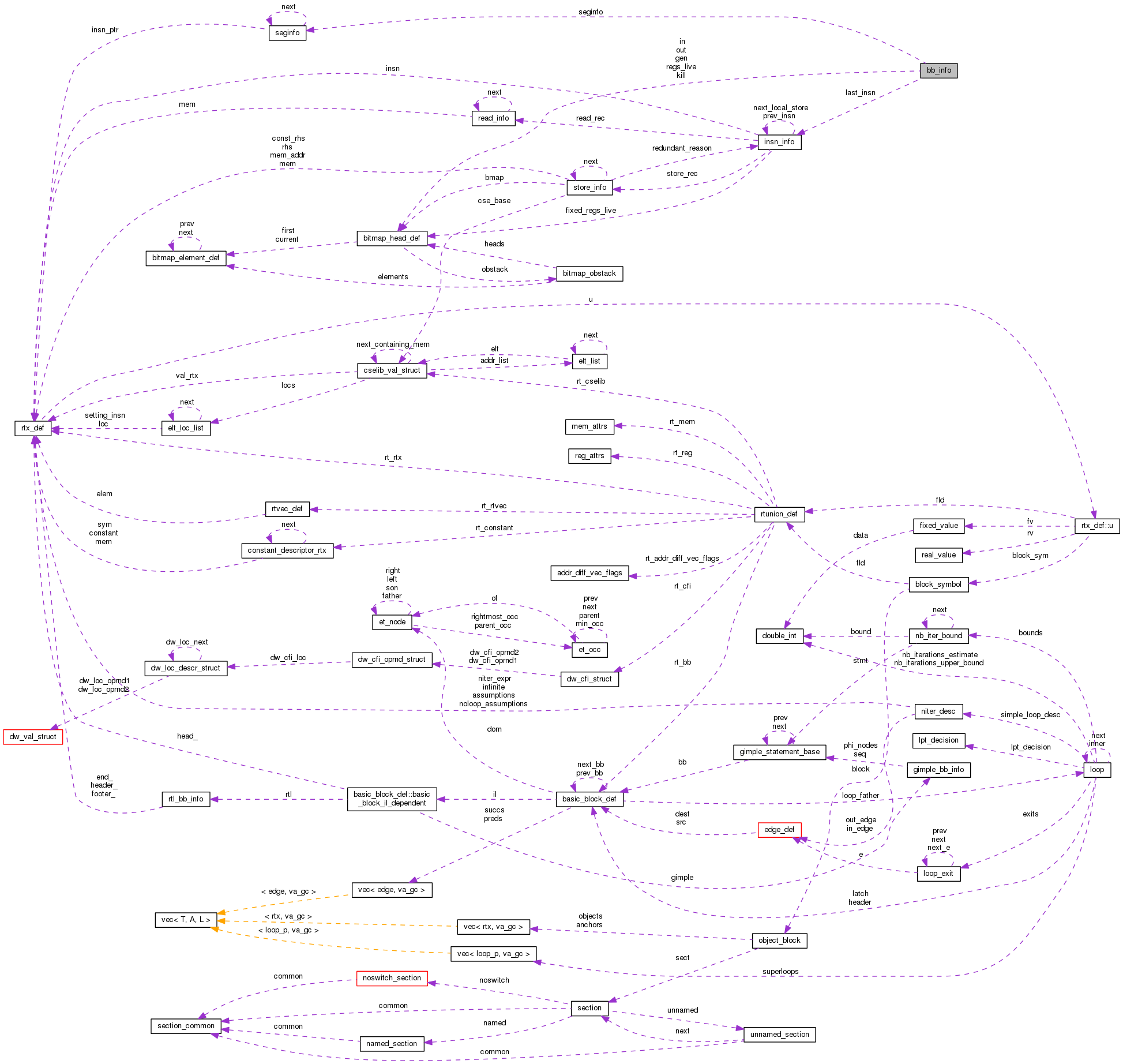
Data Fields | |
| insn_info_t | last_insn |
| bool | apply_wild_read |
| bitmap | gen |
| bitmap | kill |
| bitmap | in |
| bitmap | out |
| bitmap | regs_live |
| unsigned int | size |
| unsigned int | time |
| struct seginfo * | seginfo |
| int | computing |
| unsigned int | count_valid: 1 |
| gcov_type | succ_count |
| gcov_type | pred_count |
Detailed Description
@verbatim
Function splitting pass Copyright (C) 2010-2013 Free Software Foundation, Inc. Contributed by Jan Hubicka jh@suse.cz
This file is part of GCC.
GCC is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3, or (at your option) any later version.
GCC is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with GCC; see the file COPYING3. If not see http://www.gnu.org/licenses/.
The purpose of this pass is to split function bodies to improve
inlining. I.e. for function of the form:
func (...)
{
if (cheap_test)
something_small
else
something_big
}
Produce:
func.part (...)
{
something_big
}
func (...)
{
if (cheap_test)
something_small
else
func.part (...);
}
When func becomes inlinable and when cheap_test is often true, inlining func,
but not fund.part leads to performance improvement similar as inlining
original func while the code size growth is smaller.
The pass is organized in three stages:
1) Collect local info about basic block into BB_INFO structure and
compute function body estimated size and time.
2) Via DFS walk find all possible basic blocks where we can split
and chose best one.
3) If split point is found, split at the specified BB by creating a clone
and updating function to call it.
The decisions what functions to split are in execute_split_functions
and consider_split.
There are several possible future improvements for this pass including:
1) Splitting to break up large functions
2) Splitting to reduce stack frame usage
3) Allow split part of function to use values computed in the header part.
The values needs to be passed to split function, perhaps via same
interface as for nested functions or as argument.
4) Support for simple rematerialization. I.e. when split part use
value computed in header from function parameter in very cheap way, we
can just recompute it.
5) Support splitting of nested functions.
6) Support non-SSA arguments.
7) There is nothing preventing us from producing multiple parts of single function
when needed or splitting also the parts. Per basic block info.
@verbatim
Calculate branch probabilities, and basic block execution counts. Copyright (C) 1990-2013 Free Software Foundation, Inc. Contributed by James E. Wilson, UC Berkeley/Cygnus Support; based on some ideas from Dain Samples of UC Berkeley. Further mangling by Bob Manson, Cygnus Support.
This file is part of GCC.
GCC is free software; you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation; either version 3, or (at your option) any later version.
GCC is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with GCC; see the file COPYING3. If not see http://www.gnu.org/licenses/.
Generate basic block profile instrumentation and auxiliary files. Profile generation is optimized, so that not all arcs in the basic block graph need instrumenting. First, the BB graph is closed with one entry (function start), and one exit (function exit). Any ABNORMAL_EDGE cannot be instrumented (because there is no control path to place the code). We close the graph by inserting fake EDGE_FAKE edges to the EXIT_BLOCK, from the sources of abnormal edges that do not go to the exit_block. We ignore such abnormal edges. Naturally these fake edges are never directly traversed, and so *cannot* be directly instrumented. Some other graph massaging is done. To optimize the instrumentation we generate the BB minimal span tree, only edges that are not on the span tree (plus the entry point) need instrumenting. From that information all other edge counts can be deduced. By construction all fake edges must be on the spanning tree. We also attempt to place EDGE_CRITICAL edges on the spanning tree. The auxiliary files generated are <dumpbase>.gcno (at compile time) and <dumpbase>.gcda (at run time). The format is described in full in gcov-io.h.
??? Register allocation should use basic block execution counts to give preference to the most commonly executed blocks.
??? Should calculate branch probabilities before instrumenting code, since then we can use arc counts to help decide which arcs to instrument.
Field Documentation
| bool bb_info::apply_wild_read |
The info for the global dataflow problem.
This is set if the transfer function should and in the wild_read
bitmap before applying the kill and gen sets. That vector knocks
out most of the bits in the bitmap and thus speeds up the
operations.
| int bb_info::computing |
| unsigned int bb_info::count_valid |
| bitmap bb_info::gen |
The following 4 bitvectors hold information about which positions
of which stores are live or dead. They are indexed by
get_bitmap_index. The set of store positions that exist in this block before a wild read.
Referenced by find_insn_before_first_wild_read(), scan_reads_nospill(), and scan_stores_spill().
| bitmap bb_info::in |
The set of stores that reach the top of the block without being
killed by a read.
Do not represent the in if it is all ones. Note that this is
what the bitvector should logically be initialized to for a set
intersection problem. However, like the kill set, this is too
expensive. So initially, the in set will only be created for the
exit block and any block that contains a wild read.
| bitmap bb_info::kill |
The set of load positions that exist in this block above the
same position of a store.
Referenced by scan_stores_nospill(), and scan_stores_spill().
| insn_info_t bb_info::last_insn |
Pointer to the insn info for the last insn in the block. These
are linked so this is how all of the insns are reached. During
scanning this is the current insn being scanned.
Referenced by can_escape(), dse_step3(), and scan_stores_nospill().
| bitmap bb_info::out |
The set of stores that reach the bottom of the block from it's
successors.
Do not represent the in if it is all ones. Note that this is
what the bitvector should logically be initialized to for a set
intersection problem. However, like the kill and in set, this is
too expensive. So what is done is that the confluence operator
just initializes the vector from one of the out sets of the
successors of the block.
Referenced by dse_step3(), find_insn_before_first_wild_read(), and scan_reads_spill().
| gcov_type bb_info::pred_count |
| bitmap bb_info::regs_live |
The following bitvector is indexed by the reg number. It
contains the set of regs that are live at the current instruction
being processed. While it contains info for all of the
registers, only the hard registers are actually examined. It is used
to assure that shift and/or add sequences that are inserted do not
accidentally clobber live hard regs.
Referenced by check_mem_read_rtx().
| struct seginfo* bb_info::seginfo |
Referenced by add_seginfo().
| unsigned int bb_info::size |
| gcov_type bb_info::succ_count |
Number of successor and predecessor edges.
| unsigned int bb_info::time |
The documentation for this struct was generated from the following files:
